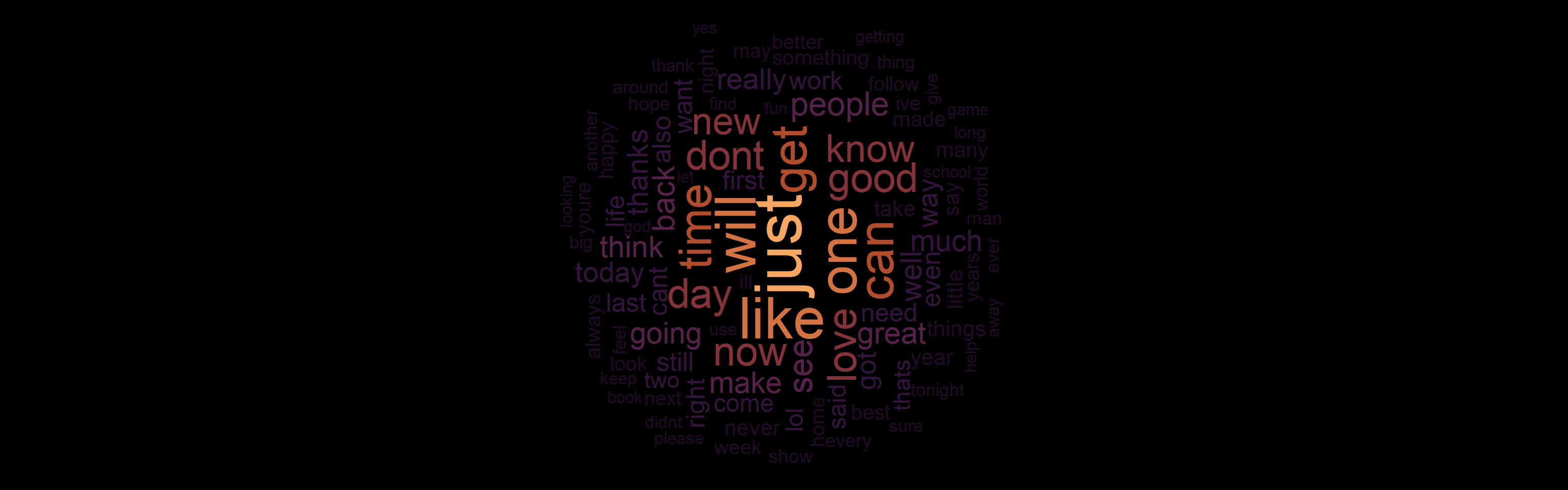
Text Prediction
GitHub Repo Web Application Exploratory Data Analysis Article
Background
Around the world, people are spending an increasing amount of time on their mobile devices for a wide range of activities. Microsoft SwiftKey builds smart keyboards that makes it easier for people to generate text on their mobile devices. When someone types:
“I went to the “
the keyboard presents three options for what the next word might be. For example, the three words might be gym, store, restaurant. The focus of this project is to understand and build a predictive text model like those used by SwiftKey.
The project analyzes a large corpus of text documents to discover the structure in the data and find how words are put together. It will cover two main topics:
- Cleaning and analyzing text data
- Building and sampling from a predictive text model
1. Exploratory Analysis
Three text files containing collections of blogs, news, and tweets were read in and cleaned to create a corpus of text, which was used to construct N-gram models. The focus was on the frequency of words, unigrams, bigrams, and trigrams. A word cloud and several bar charts were constructed in R for visual aid which can be found in the detailed walkthrough of the data cleaning and exploratory analysis processes here.
2. Web Application
The web application was built using Shiny. The user interface presents the predictive model that makes the best guess of what the next word of an incomplete sentence will be. Simply enter a partial sentence in the input field and the predicted next word will be generated in live time. Users can also view statistics of the text corpus by toggling between bar charts of the most frequently occurring N-grams. We currently support unigrams, bigrams, and trigrams.
GitHub Repo Web Application Exploratory Data Analysis Article